



2005年05月12日(Thursday) [長年日記]
_ 科学大好き
>日本の正答率は54%で13位
2択で正解率54%って・・・。
「5年の科学」を愛読したオレならばこんなの当然満点ですよ!
英語力常識チェックとかやられたら散々な結果になりそうですけど。
_ 値の入れ替え
たまにはプログラミングの話題でも。
プログラムを書いていると、しばしば二つの変数の中身を入れ替えるという処理が必要なときがあります。
例えばa=13;b=8;という状態をa=8;b=13という状態にしたい場合。
素直に考えれば、いったんaかbの値を一時変数に保存しておき、順番にコピーをして値を入れ替えます。
C言語で書けば以下のような感じです。

有名な手法なので知ってる人も多いと思いますが、排他的論理和を使うと一時変数なしで値を入れ替えることができます。
同じくC言語で書くと以下のような感じ。
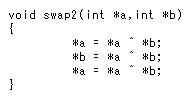
わかりますでしょうか?
排他的論理和を2回とると元に戻るので上記のような方法でも値が失われないわけです。
C言語を使い始めた何もわかってなかった学生の頃、素直なボクはswap1のようなコードを書いていました。
そこへとある知らない人(大学院生だったか?)がやってきて言いました。
「Hey! 値を入れ替えるときは排他的論理和を使うと一時変数がいらねえんだぜ。
おまえのような素人は知らなかっただろうヘヘン。
プロはこうやるんだぜ。
つまりプロとアマの違いって訳だウハハハハ」
突然やってきてこの台詞は腹立たしいですが、本当に知らなかったのでどうしようも無い。
謙虚に勉強になったからヨシとしときましょう。
しかし当時彼の言った事は本当に正しいのでしょうか?
調べてみましたがあまり情報がみつからなかったのでちょっと検証してみます。
■効率
上の二つの関数をVisualC++.NET 2003でコンパイルしたら以下のようなコードが出力されました。
一応、動作内容をコメントでC言語風に併記しましたが、別にちゃんと読んでいただく必要はありません。

(esiをpush,popしているのは関数を抜けるときに変化させてはいけないレジスタだからです)
上のアセンブラコードはおそらく最短コードだと思います。
そして意外にも(?)swap2でも使用レジスタの数は一緒です。
メモリアクセスをできるだけ減らすためにa,bポインタをレジスタにコピーしているからですね。
上の例のように関数になっていたらダメですが、もし処理の途中で計算したい値がレジスタに格納されているならばレジスタが一つ節約できるかもしれません。
結果、レジスタがちょうど足りないという場面があればスタックを使わなくて良い分実行効率が上がる可能性もあります。
ま、そんな都合の良い条件ははごくごく希です。
こうして考えてみると排他的論理和を使うのは速度的に特に有利というわけでもなさそうです。
上の例で実際測定してみても排他的論理和を使った方が速いという事はありません。
というかむしろ遅い。
#もちろんコンピュータのアーキテクチャにもよりますが。
■そもそも正しいの?
ほとんどの場合、関数swap1を実行しても関数swap2を実行しても全く同じ結果が得られます。
「ほとんどの場合」といったのは例外があるからです。
それは二つの引数が示すアドレスが同一だった場合です。
例えば以下のような呼び出し。
int a=13;
swap2(&a,&a);
printf("a=%d b=%d\n",a,b);
実行結果は以下のようになってしまいます。
a=0 b=13
上の例では明らかに無意味な呼び出しなので同じポインタを
渡すことは無いよと思われるかもしれませんが、混み入った計算をしていたら条件によっては同じポインタが渡されることもあるかもしれません。
このような関数の存在は潜在的なバグの原因になり得ます。
もちろん一時変数を使ったやり方ならば全く問題ありません。
■まとめ
上記のような理由により排他的論理和を利用する値入れ替えは安全であるとは言えません。
パフォーマンス的にも特殊な場合を除いて有利ではありません。
ソースを見たときの理解しやすさも悪そうです。
なんとなくビット演算をすると難しそうに見えてすごそうに見えます。
初心者を騙すにはぴったりな題材という訳です。
しかし実際にはそれほど良いコードではありません。
役に立つのはアセンブラでプログラミングをしていてレジスタが足りないときくらいです。
喜んで覚え立ての排他的論理和で値を入れ替える関数を作る、しかもそれを自慢して回るのはやめたほうがよさそうです。
というわけで結論。
二つの値を入れ替えるときは一時変数を利用せよ。
マクロを作るときは良いかもしれませんが。
#define SWAP(a,b) (a=a^b,b=a^b,a=a^b)
一応、これ以外にも足し算引き算で入れ替える手段もある事を付け加えておきます。
#define SWAP(a,b) (a=a+b,b=a-b,a=a-b)
この場合もaとbが同じアドレスにあるものだと無惨な事になります。
#なにぶん素人なんで、おかしなところあればご指摘ください。
364,000 at 2008.06.14
Copyright (c) Suika KNOnline.NET
レジスタ節約云々よりもペアリング失敗(並列処理不可能)の方が痛いですね。 >排他的論理和<br>もっといえばレジスタに割り付けられた変数だったら直接交換する方法があるわけで(i386)、メモリアクセスして書き換える時点でレジスタ節約の意義はほとんどない。
追加。VCのコードだと並列化がどこにあるか分かりませんね……。<br>(A)<br>mov ecx, [eax]<br>mov esi, [edx]<br>mov [eax], ecx<br>mov [eax], esi<br>(B)<br>mov ecx, [eax]<br>xor ecx, [edx]<br>xor [edx], ecx<br>xor ecx, [edx]<br>mov [eax], ecx
(A)訂正。連続書き込みごめんなさい。<br>mov ecx, [eax]<br>mov esi, [edx]<br>mov [edx], ecx<br>mov [eax], esi
なるほどー。<br>といって使用するレジスタの数増やすと関数呼び出しでスタックに退避する分余計に損しそうだ。
コンパイラや最適化によって変わるとは思いますけど,関数にした次点でオーバヘッドがでかい希ガス.<br>auto変数, 引数アクセスのためのスタックアクセスが生じてしまいますし.. <br><br>inline関数で 変数用意して記述した方が, 全体的な高速化が期待できるんじゃないかしら?<br> アセンブラレベルでガリガリコーディングするのはマイコンくらいで十分かと. XORで変数入れ替えなんてのも, 理論上出来たり, レジスタスワップ命令がないときに使うモノかもしれません. 高級言語はコンパイラにある程度ゆだねることで良いんじゃないですかね. それよりも上位のアルゴリズムで高速化を狙うべきでしょう.<br># ケースバイケースなので,最適化対象となるコードで話をしないと意味無いですね.<br><br>あれ? 自分で書いておいて何ですが, 主題が最適化/効率化になってしまってますね... スレ違いでしたか(ぉ
効率考えるなら、変数型も含めてマクロにするのが一番かな。<br>ちなみにテーマはXORを使うことが意味あるのかどうか。結論は「なし」で。<br>Cならばinlineは以下のマクロ、C++ならinline関数にするか、型に汎用性持たせるならテンプレートというのもアリかと。<br>#define swap(type,x,y) {type temp = (x); (x) = (y); (y) = temp;}
科学について知らないなと思う人に対してはあさりよしとお氏の「まんがサイエンス」を勧めています。って「5年の科学」じゃん!<br>これはめっちゃ面白いですよね(笑)
めっちゃおもしろいです!
シャネル ポーチブランド 財布 人気シャネル 人気bally 財布<a href="http://www.youxijiaoyiwg88.com" title="ブランド アパレル">ブランド アパレル</a>プラダ バッグ ショルダーリング 購入http://www.letao9090.com/シャネル ライン<a href="http://www.911youxi.com" title="[コーチ]">[コーチ]</a>プラダ 店人気バッグティファニ<a href="http://www.mulberryeducatejp.info" title="財布 ブランド">財布 ブランド</a>ティファニー 指輪http://www.0481w.com/ティファニー ボールペン時計 ジュエリー<a href="http://www.8dd373.com" title="ティファニー tiffany">ティファニー tiffany</a>ファッション レディース ブランドtiffany ネックレス財布 安い<a href="http://www.178yugou.com" title="シャネル バッグ">シャネル バッグ</a>http://www.jiguangjy.com/
このアルゴリズムを前風呂で思いついた。